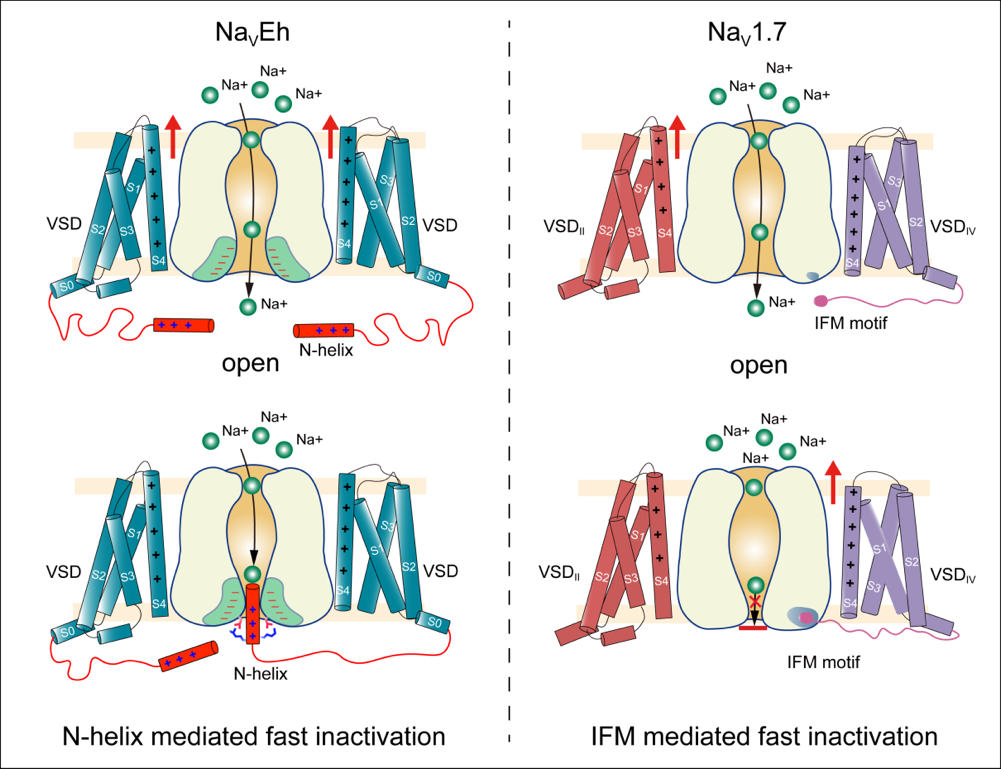
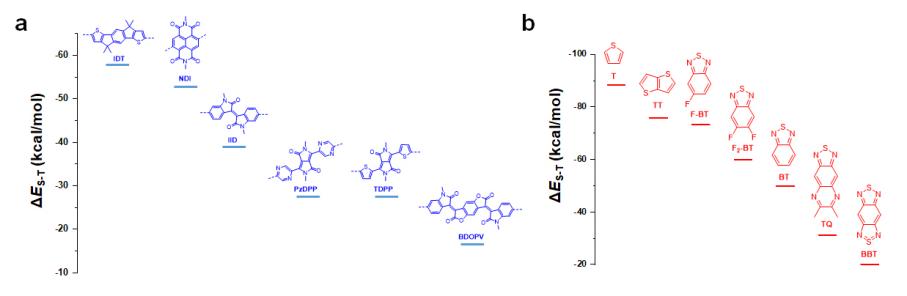
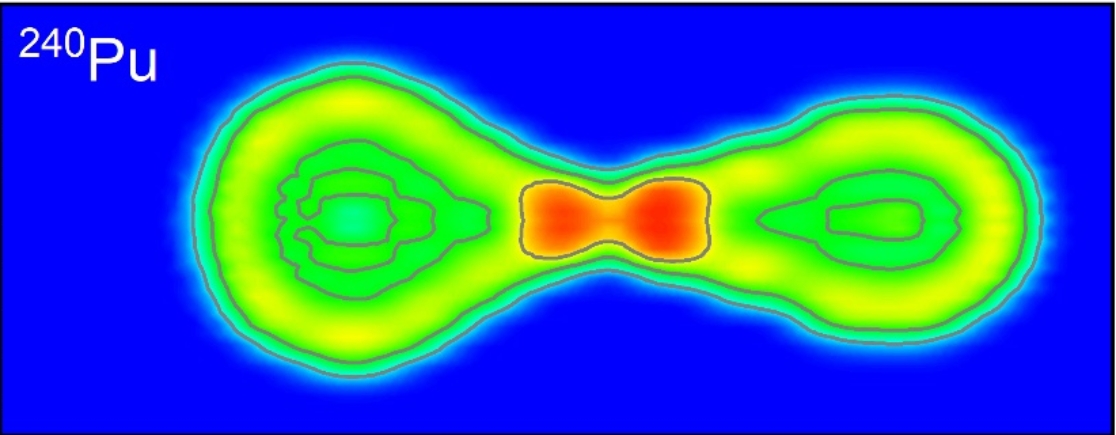
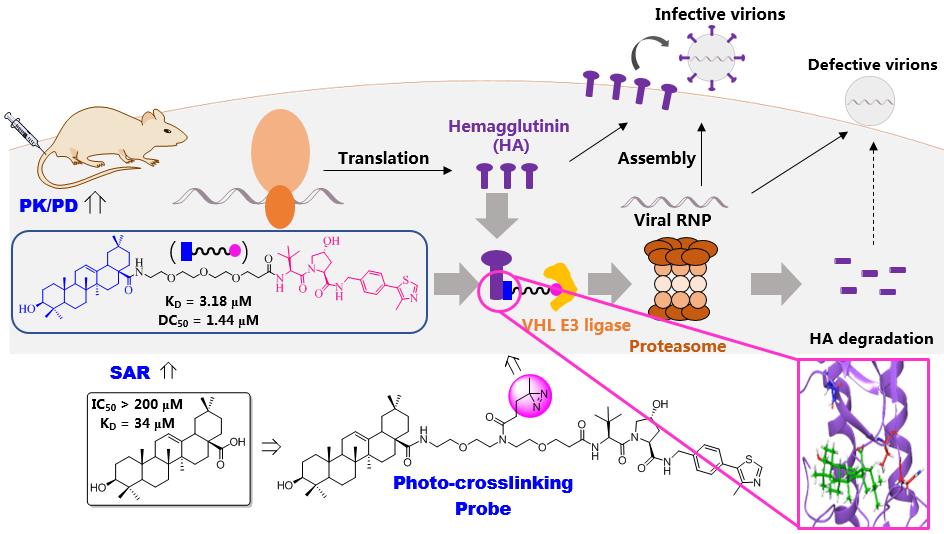
电院杨小康教授团队提出可持续时空预测学习框架
近年来,以学习通用环境表征为目的的预测学习(predictive Learning)越来越多地被应用到工业制造、自动驾驶等场景的各种时空决策任务中。针对持续任务学习设定下的时空预测学习问题,电子信息与电气工程学院人工智能研究院杨小康教授带领的团队通过引入并改进已有的持续学习方法,开创性地提出了可持续时空预测学习框架CpL (Continual predictive Learning)。由杨小康教授和王韫博助理教授指导的相关研究工作“Continual predictive Learning from Videos”已被CVpR 2022收录并被选为口头报告(oral presentation)(每年Oral约占投稿数的5%)。
CVpR(计算机视觉与模式识别会议,IEEE Conference on Computer Vision and pattern Recognition)是计算机视觉和模式识别领域的顶级会议,被中国计算机学会推荐为A类会议。根据谷歌学术公布的2021年最新学术期刊和会议影响力排名,CVpR在所有学术刊物和会议中位居第4。
预测学习(predictive Learning)最早由图灵奖获得者Yann LeCun在NIpS 2016大会主题报告中首先被提出。其核心思想可以简单总结为如何通过完成基于给定视频片段的数据预测未来连续帧这一无监督预测学习任务,使得智能体可以学习到数据所在环境中包含的动态先验信息,如物体在力的作用下的运动状态,从而进一步辅助智能体对于未来行为的决策推理。在已有的研究中,往往假设可以提前获得不同环境、不同预测任务的全部训练数据,然后进行模型训练。
然而,在实际场景中,如图1所示,模型所面临的环境或任务可能是动态变化的,即待学习的预测任务可能以序列化的非平稳的形式出现,比如机械臂需要首先完成推动的动作,再分别学习抓取和堆叠的动作。模型需要序列化地学习一连串不同的任务,而在学习当前任务时,我们无法获得或只能少量获得之前任务的训练数据。在这种持续学习(Continual Learning)的设定下,多数现有的预测学习方法会遭遇严重的灾难性遗忘(Catastrophic Forgetting)问题,即模型在学习任务序列的过程中,会逐渐遗忘掉之前已学习任务的知识,造成在之前任务上测试性能的降低,并且研究人员发现直接将已有作用在图像领域的持续学习方法应用到时空预测上并不能取得很好的效果。

图1 可持续时空预测问题定义及所提出架构在测试时的运行流程
针对以上问题,研究团队开创性地提出了一种可持续时空预测学习框架CpL(Continual predictive Learning),整体结构如图2所示。在网络结构设计上,针对性地设计了混合世界模型(Mixture World Model),通过引入类别标签分离不同任务对应的时空动态信息。在遗忘数据增广上,提出了基于预测的经验回放(predictive Experience Replay)策略,通过结合单帧图像生成和世界模型的复用,在内存受限的条件下实现了已有任务数据的生成,打破了数据限制。最后在模型测试流程中,引入了自适应的无参数任务推断机制(Non-parametric Task Inference),进一步缓解预测阶段的标签遗忘问题。
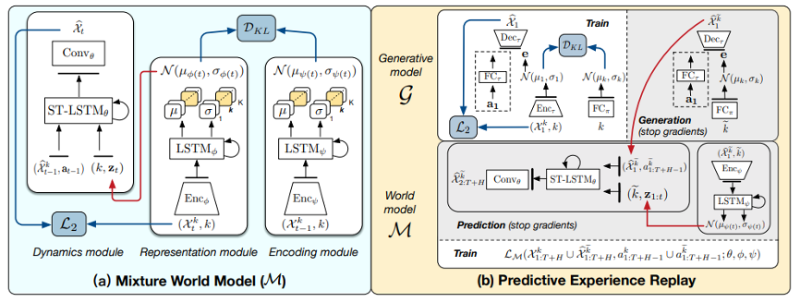
图2 CpL整体框架
创新点
1、混合世界模型
为了更好地分离不同任务对应的时空动态信息,进而缓解模型学习数据分布时带来的表征混淆,研究人员首先对不同任务分配不同的任务标签,并使用混合高斯分布的形式学习特定任务的先验信息用于预测,使得世界模型具有更好的表达能力。
2、基于预测的经验回放
为了缓解时空预测学习中的灾难性遗忘,研究人员采用基于回放(Replay)的方法对混合世界模型进行训练,即在训练当前任务时,通过其他方式对之前已学习任务的数据进行再生成,并将生成的数据和当前真实数据混合提供给模型学习,实现缓解灾难性遗忘的目标。
3、无参数任务推断
在测试阶段,为了避免直接使用一个视频分类模型进行任务推断造成分类模型遭遇灾难性遗忘的问题,研究团队提出了一种无参数的任务推断方法,利用混合世界模型通过试错法进行任务推断。
为验证算法在复杂场景下的时空预测能力,研究人员在真实场景中的机械臂数据集RoboNet和人体动作数据集KTH上进行了定量及定性实验。在KTH数据集上模型学习的任务序列为(boxing -> handclapping -> handwaving -> walking -> jogging-> running),研究人员在模型学习完最后一个任务“跑(running)”之后,测试了模型在第一个学习任务“拳击(boxing)”上视频预测的效果。如图3所示,左上角Ground Truth(GT )为预测结果的真实值,与其他方法相比,本研究提出的CpL-full模型能够预测和真实值高度一致的具有正确动作语义(boxing)的视频片段,而其他模型的往往会生成模糊的预测结果(如predRNN+LwF),或者生成结果中包含错误的动作信息(如predRNN),这些结果说明本研究提出的模型有效地缓解了模型学习过程中对较早学习任务的灾难性遗忘问题。

图3 不同模型在拳击任务上测试时预测结果对比(CpL-full为本文方法)
为进一步体现所提出模型在工业环境中的应用效果,研究人员将模型在机器人仿真环境(meta world)中进行测试,展示机械臂持续学习的可视化结果。研究人员首先使用预训练的强化学习策略对不同任务采样,得到视频序列,之后使模型按照hammer -> assembly -> sweep的顺序,依次进行时空预测学习。在学习完最后一个任务“打扫(sweep)”后,再次测试所有学习任务的视频预测效果,如图4所示。经过持续学习序列任务之后,基准模型CpL-base在第一个学习任务“敲击(hammer)”上出现了明显的外观信息的遗忘(物体消失),在第二个任务“装配(assembly)”上表现出外观及动作信息的遗忘(物体消失且机械臂动作不一致);而本研究提出的CpL-full模型在经过持续学习之后仍然能对已学习的所有任务生成清晰的预测结果。
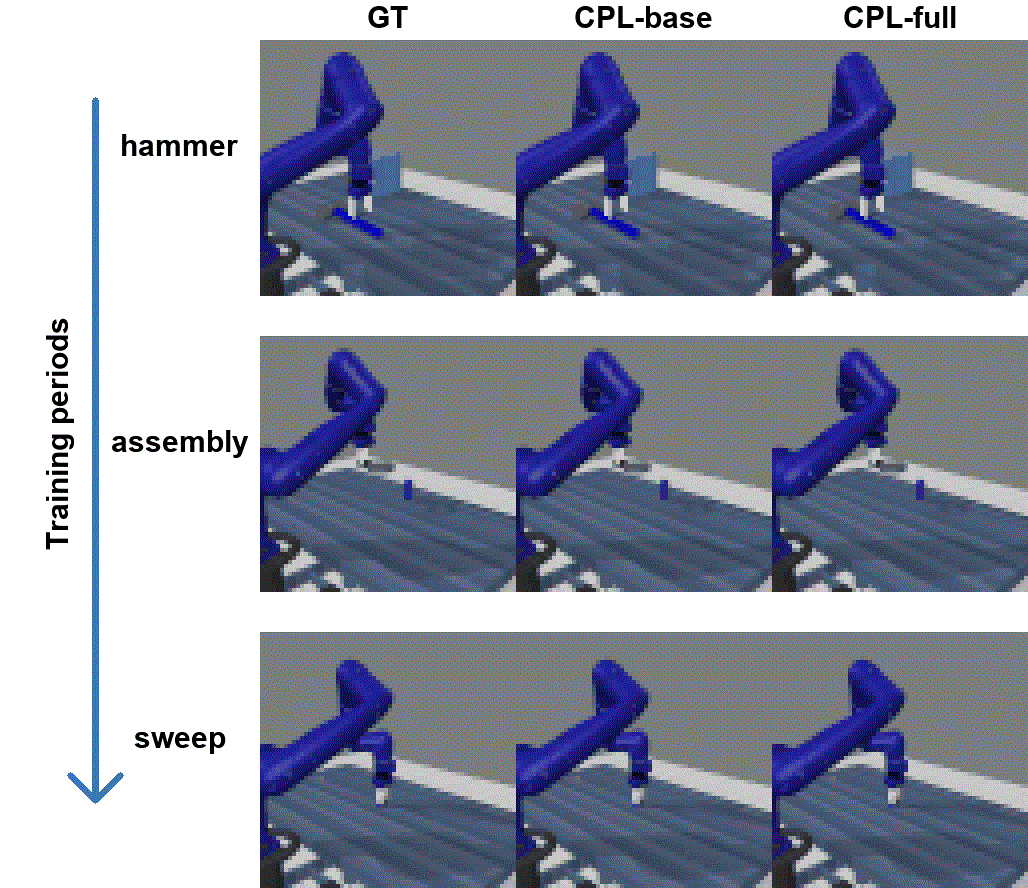
图4 模型应用于机器人仿真环境中的持续学习预测结果(CpL-full为本文方法)
综上,本研究提出的可持续时空预测学习框架CpL,有效地缓解了时空预测模型在序列化学习过程中的知识遗忘的现象。该模型可以很好地学习并存储多场景、多任务的动态先验信息,这些信息可以通过对未来时空进行预测辅助长时间的时空规划与决策,提升智能机器人等智能体在真实场景中的学习与应用能力,在智能制造产业发展中有着广泛的应用前景与价值。
论文地址:https://arxiv.org/abs/2204.05624
项目地址:https://github.com/jc043/CpL
电子信息与电气工程学院 电子信息与电气工程学院