Nature子刊:一种能绘制蛋白质潜能的新技术
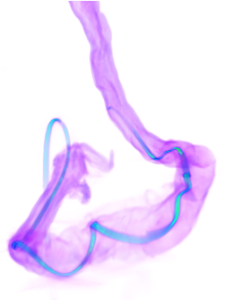
图示:考虑到图形的几何形状,该图描述了两个蛋白质之间的最短路径。通过以这种方式定义距离,有可能获得生物学上更精确和更有力的结论。(资料来源:W. Boomsma, N. S. Detlefsen, S. Hauberg)
资料来源:W. Boomsma, N. S. Detlefsen, S. Hauberg。
生物技术行业一直在寻找完美的突变,将不同蛋白质的特性进行合成组合,以达到预期的效果。可能有必要开发新的药物或酶,以延长酸奶的保质期,在野外分解塑料,或使洗衣粉在低温下有效。
DTU计算机和哥本哈根大学(DIKU)计算机科学系的新研究从长远来看可以帮助业界加速这一进程。在《自然通讯》(Nature Communications)杂志上,研究人员解释了一种使用机器学习(ML)绘制蛋白质图谱的新方法,这使得指定需要更仔细检查的蛋白质候选列表成为可能。
近年来,我们已经开始使用机器学习来形成蛋白质允许突变的图像。然而,问题是,你得到的图像取决于你使用的方法,即使你多次训练同一个模型,它也可以提供不同的答案,关于生物学是如何相关的。
“在我们的工作中,我们正在研究如何使这一过程更强大,我们正在展示,你可以提取比以前多得多的生物信息。DTU计算机学院认知系统部门的博士后Nicki Skafte Detlefsen说:“这是向前迈出的重要一步,以便能够探索具有特殊属性的蛋白质的突变景观。”
蛋白质的图谱一个蛋白质是一条氨基酸链,当这些氨基酸链中的一个被另一个取代时,就发生了突变。由于天然氨基酸有20种,因此突变的数量增加得如此之快,完全不可能研究全部。可能的突变比宇宙中原子的数量还要多,即使你只看简单的蛋白质。不可能用实验的方式测试所有的东西,所以你必须对你想要合成的蛋白质有选择性。来自DIKU和DTU计算机的研究人员使用他们的ML模型生成了蛋白质如何连接的图片。通过展示许多蛋白质序列的模型,它学会了为每个蛋白质画一张标有点的卡片,这样,密切相关的蛋白质就会彼此靠近,而远相关的蛋白质就会彼此远离。ML模型是在数学和几何基础上开发的绘制地图。想象一下,你必须画一幅地球地图。如果你放大丹麦,你可以很容易地在一张纸上画一幅地图,以保存其地理位置。但是如果你一定要画地球,就会出现错误,因为你把地球拉长了,使北极变成了一个很长的国家,而不是一个极点。所以,在地图上,地球是扭曲的。因此,在地图制作的研究中,已经发展出许多描述地图失真和补偿地图失真的数学。这正是DIKU和DTU计算能够扩展到蛋白质的机器学习模型(深度学习)的理论。因为他们已经掌握了地图上的失真,他们也可以补偿它。“它使我们能够讨论密切相关的蛋白质之间的合理距离目标,然后我们突然可以测量它。通过这种方式,我们可以在蛋白质图谱中绘制出一条路径,它告诉我们一个蛋白质应该以何种方式发展成另一个蛋白质——即突变,因为它们都与进化有关。通过这种方式,ML模型可以测量蛋白质之间的距离,并在有希望的蛋白质之间绘制最佳路径,”DIKU机器学习部门的副教授Wouter Boomsma说。
从众多的研究人员测试了模型数据在自然界中发现的蛋白质,其结构是已知的,他们可以看到,蛋白质之间的距离开始对应蛋白质的进化发展,所以蛋白质散播他们的相互接近放置接近对方。
“我们现在能够把两种蛋白质放在地图上,并画出它们之间的曲线。在这两个蛋白质之间的路径是可能的蛋白质,它们具有密切相关的特性。这不能保证,但它提供了一个机会,让我们有一个假设,即当设计出新的蛋白质时,生物技术行业应该测试哪些蛋白质。”DTU计算机学院认知系统部分的教授索伦·豪伯格(S?ren Hauberg)说。DTU计算和DIKU之间的独特合作是通过一个新的生命科学机器学习中心(MLLS)建立的,该中心于去年在诺和诺德基金会的支持下启动。在该中心,来自两所大学的人工智能研究人员正在合作,解决由生物学领域的重要问题驱动的机器学习的基本问题。开发的蛋白质图谱是一个从基础研究到工业应用的大型项目的一部分,例如与诺维信和诺和诺德合作。
FACT BOX:人工智能、机器学习和深度学习
当计算机程序能够做一些“智能”的事情时,它被称为人工智能,或者只是AI。因此,人工智能是一个包含多种方法的统一概念。其中一种方法是机器学习,机器学习的最新和最先进的应用被称为深度学习。深度学习基于神经网络,神经网络是一种数学模型,模型本身来自给定的数据集,不需要直接编程就可以学习发现数据中的模式。因为您使用数据,所以它被称为数据驱动模型。在无监督学习中,目标是训练神经网络来发现数据中的潜在模式。这通常是通过尝试压缩数据来实现的,因为这样可以拒绝数据中最不频繁的趋势,而最重要的数据则占用更多的信息,这样您就可以看到底层模式。通过多次重复,网络了解哪些数据模式可以用来压缩数据。一旦模型经过训练,它就会在未知数据上进行测试,然后这些数据也可以被压缩成一个紧凑的表示,可以被解释为形成科学假设或形成其他机器学习模型的基础。